
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 카카오인턴십
- istringstream
- ChatGPT
- 독일어독학
- 부주상골증후군
- BFS
- 구현
- SQLD
- 코딩테스트
- 스택
- 리눅스
- 세브란스
- 프로그래머스
- 코테
- 부주상골
- 카카오코테
- 독일어
- 독학
- c++
- 백준
- SWIFT
- 부주상골수술후기
- 부주상골수술
- 롯데정보통신
- 분할정복
- 카카오인턴
- DFS
- IOS
- dp
- sql
- Today
- Total
슈뢰딩거의 고등어
[알고리즘] 정렬 본문
면접 예상 질문
정렬 방식 중 알고 있는 방식을 말해보시오.
정렬 방식의 종류 중에서 가장 효율적인 정렬 방식을 말해보시오.
퀵 정렬에 대해서 말해보고, 어떤 장점이나 효율이 있는지 말해보시오.
답변 핵심 Keyword
퀵 정렬, 버블 정렬, 선택 정렬, 삽입 정렬, 병합 정렬, 시간 복잡도
올바른 정렬 방식을 선택하고 구현하는 것은 프로그램 개발에 있어서 기본적으로 생각해야 할 필요한 지식이고, 또 그런 식의 효율적인 사고를 할 수 있는가는 프로그래머의 역량이라고 생각할 수도 있다. 귀찮으니까 3번 반복문을 돌려 개발하면 된다는 식은 곤란한 상황으로 빠질 수도 있다.
버블 정렬
정렬을 하는 것을 어떻게 할지 생각해보면 대표적으로 과거에는 학교에서 키 순서대로 앞자리부터 앉게 하곤 했는데, 그러려면 학생들 모두 일어서게 하고, 한 줄로 선 다음에 두 사람씩 서로 키를 비교해보고 키가 작은 사람을 앞으로 보내면 된다. 그렇게 하다 보면 몇 번의 반복 끝에 키 순서대로 서게 될 것이다. 이것은 모든 학생이 사람이고 거의 동시에 서로 간의 키를 대조해서 앞으로 보내주면 되기 때문에 비효율적으로 보이진 않는다. 이러한 정렬을 공기 방울이 물 안에서 위로 올라오는 형상과 비슷하다고 하여 버블 정렬이라고 한다. 그런데, 알고리즘적으로 이 방식이 아주 효율적인 것은 아니다.
버블 정렬보다 효율을 높인 정렬은 몇 가지가 있다. 선택 정렬, 병합정렬, 삽입정렬, 퀵 정렬 등이 있다.
선택정렬
여러 가지 숫자들이 있고, 오름차순으로 정렬을 한다고 했을 때. 데이터 중 가장 작은 원소를 찾아 가장 앞으로 보내고, 나머지 데이터들 중 가장 작은 데이터를 찾아 그다음으로 위치시키는 형식의 정렬방법이다. 시간 복잡도는 n^2이다.

[선택 정렬 c++ 코드]
#include <iostream>
#include <vector>
using namespace std;
int arr[10] = {8, 6, 5, 3, 1, 2, 7, 4, 9, 0};
void selection_sort() {
for(int i=0; i<10; i++) {
int min = arr[i];
int target = i;
for(int j=i+1; j<10; j++) {
if(min > arr[j]) {
target = j;
min = arr[j];
}
}
swap(arr[i], arr[target]);
}
}
int main() {
selection_sort();
for(int i=0; i<10; i++) {
printf("%d ", arr[i]);
}
}
삽입 정렬
숫자들을 정렬할 때 앞에서부터 진행을 할 때, 그 범위를 점차 늘려가면서 다음 나오는 숫자를 맞는 위치에 삽입을 시켜주면서 진행을 한다. 만약 앞에 정렬된 숫자들보다 크면 그대로 넘어가고 작다면 올바른 위치를 찾아줘서 넣는다. 그러다 보면 선택 정렬보다는 빠른 성능을 가질 수 있다. 하지만 최악의 경우 (내림차순으로 정렬되어있는 케이스의 경우) n^2의 시간 복잡도를 가지게 된다. 따라서, 이 경우에는 이미 정렬이 어느 정도 되어있는 상태의 케이스에 적합하다.
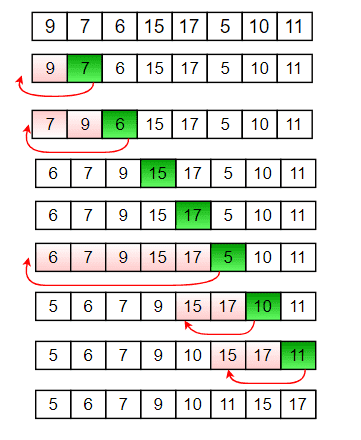
#include <iostream>
#include <vector>
using namespace std;
int arr[10] = {8, 6, 5, 3, 1, 2, 7, 4, 9, 0};
void insertion_sort() {
for(int i=0; i<10; i++) {
for(int j=0; j<i; j++) {
// swap
if(arr[j] > arr[i]) {
swap(arr[i], arr[j]);
continue;
}
}
}
}
int main() {
insertion_sort();
for(int i=0; i<10; i++) {
printf("%d ", arr[i]);
}
}
퀵 정렬
평균 O(N * logN)로 빠르다.
최악의 경우 : 이미 정렬이 되어있을 경우 n^2의 복잡도를 가진다.
숫자를 정렬할 때 하나의 pivot을 설정하고 pivot 을 기준으로 작은 값을 왼쪽, 큰 값을 오른쪽으로 배치한다. 그리고 이를 오른쪽과 왼쪽 분류 내에서도 각 pivot 을 설정하고 반복하며 수행한다.
1. pivot, i, j을 설정한다.
2. i++ 를 진행하면서 pivot 보다 큰 값을 찾는다.
3. j-- 를 진행하면서 pivot 보다 작은 값을 찾는다.
4-1) i < j 일 경우, i, j를 swap 한다.
4-2) i > j 일 경우, pivot과 j를 swap 한다.
5. 왼쪽, 오른쪽을 나눠 수행한다. quick_sort(start, j-1) quick_sort(j+1, end)
| 8 | 6 | 5 | 3 | 1 | 2 | 7 | 4 | 9 | 0 |
| pivot | i | j |
pivot 과 i, j 포인터를 설정한다.
i++ 는 pivot 보다 큰 값을 찾고, j--는 pivot 보다 작은 값을 찾는다.
| 8 | 6 | 5 | 3 | 1 | 2 | 7 | 4 | 9 | 0 |
| pivot | i | j |
i < j 일 경우, i와 j 를 swap 한다.
| 8 | 6 | 5 | 3 | 1 | 2 | 7 | 4 | 0 | 9 |
| pivot | i | j |
swap 결과
| 8 | 6 | 5 | 3 | 1 | 2 | 7 | 4 | 0 | 9 |
| pivot | j | i |
j--, i++ 를 수행하였더니 i > j 가 되었다. 이럴 경우, j와 pivot을 swap 해준다.
| 0 | 6 | 5 | 3 | 1 | 2 | 7 | 4 | 8 | 9 |
| j / pivot | i |
swap 해준 결과 pivot/j의 위치에서 왼쪽은 pivot 보다 작은 값들이 모이고, 오른쪽은 큰 값들이 모였다.
| 9 |
| start, end |
start와 end 가 같은 데이터를 가리키므로 비교할 수 있는 대상이 없다. 종료한다.
| 0 | 6 | 5 | 3 | 1 | 2 | 7 | 4 |
| pivot | i | j |
오른쪽도 같은 방식으로 진행한다. pivot, i, j를 설정한다.
| 0 | 6 | 5 | 3 | 1 | 2 | 7 | 4 |
| pivot / j | i |
pivot 보다 큰 위치 i를 구하고 pivot 보다 작은 위치 j를 구하는 과정에서 i++, j-- 를 반복적으로 수행했더니 i> j 가 되었다.
pivot / j 위치를 바꾼다. 그대로이다.
| 0 |
| start, end |
0의 위치는 이제 고정되었다.
| 6 | 5 | 3 | 1 | 2 | 7 | 4 |
| pivot | i | j |
| 6 | 5 | 3 | 1 | 2 | 7 | 4 |
| pivot | i | j |
| 6 | 5 | 3 | 1 | 2 | 4 | 7 |
| pivot | i | j |
| 4 | 2 | 3 | 1 | 5 | 4 | 7 |
| pivot | j | i | j | i |
| 4 | 2 | 3 | 1 | 5 | 6 | 7 |
| pivot / j | i |
반복한다.
#include <iostream>
#include <vector>
using namespace std;
vector <int> arr(10);
void quick_sort(int start, int end) {
if(start >= end) return;
int pivot = start;
int i = start + 1;
int j = end;
while(i <= j) {
while(i <= end && arr[i] < arr[pivot])
i++;
while(j > start && arr[j] > arr[pivot])
j--;
if(i > j) {
swap(arr[j], arr[pivot]);
}
else
swap(arr[i], arr[j]);
}
quick_sort(start, j-1);
quick_sort(j+1, end);
}
int main() {
arr = {8, 6, 5, 3, 1, 2, 7, 4, 9, 0};
quick_sort(0, 9);
for(int i=0; i<10; i++) {
printf("%d ", arr[i]);
}
}
데이터는 자료 구조 내에 저장되고 검색된다. 데이터를 효율적으로 검색하기 위한 여러 가지 방법이 있는데 대표적인 것이 '정렬'이다. 자료를 정렬하면 검색 속도가 향상된다. 이 정렬에는 다양한 방법이 있고 각 방법은 장단점을 가지고 있어 상황에 맞게 정렬 알고리즘을 사용해야 한다.
'cs 면접' 카테고리의 다른 글
| [프로그래밍 언어] c, c++, java, python 의 차이점은? (0) | 2022.02.20 |
|---|---|
| [운영체제] 프로세스 vs 쓰레드 (0) | 2022.02.18 |
| [자료구조] Tree (0) | 2022.02.13 |
| [자료구조] 배열 vs 링크드리스트 (0) | 2022.02.13 |
| [자료구조] Stack vs Queue (0) | 2022.02.13 |
